A guide to free reference and academic paper management with Zotero
Update: I recently learned that box.com plans to deprecate WebDAV support in October 2019, a decision which renderse part of the workflow described here unsustainable beyond October. As I come up with an alternative solition, I will change this post to reflect the new reality.
First things first, we need a reference manager. A reference manager stores bibliographic information for each reference, and most of them support associating the reference with a source file corresponding to the reference. Usually this is a PDF from the publisher or a scan you might have come across, but it can also be a HTML snapshot of a website or, indeed, other multimedia such as audio and video. I use Zotero.
Pretty standard stuff here. How do you get references into Zotero? Well, there’s a couple of ways. First, we can do it manually, using the GUI. A bunch of form fields will pop up; you know what to do from here.
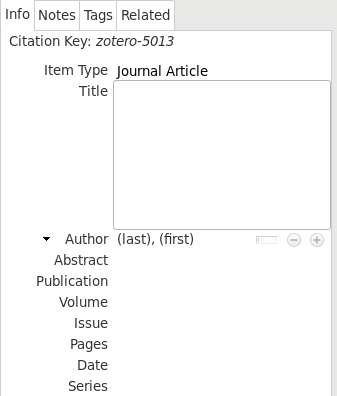
Alternatively, we can install the Zotero Connector browser extension for our favorite browser. Then, when we visit a site that appears to correspond to a reference that is understood by Zotero, an icon will appear in a toolbar reflecting the type of reference that has been detected. You can click on that icon and it will attempt to add the reference to the currently open collection in Zotero, along with the metadata deduced from the publisher’s item page (if possible)
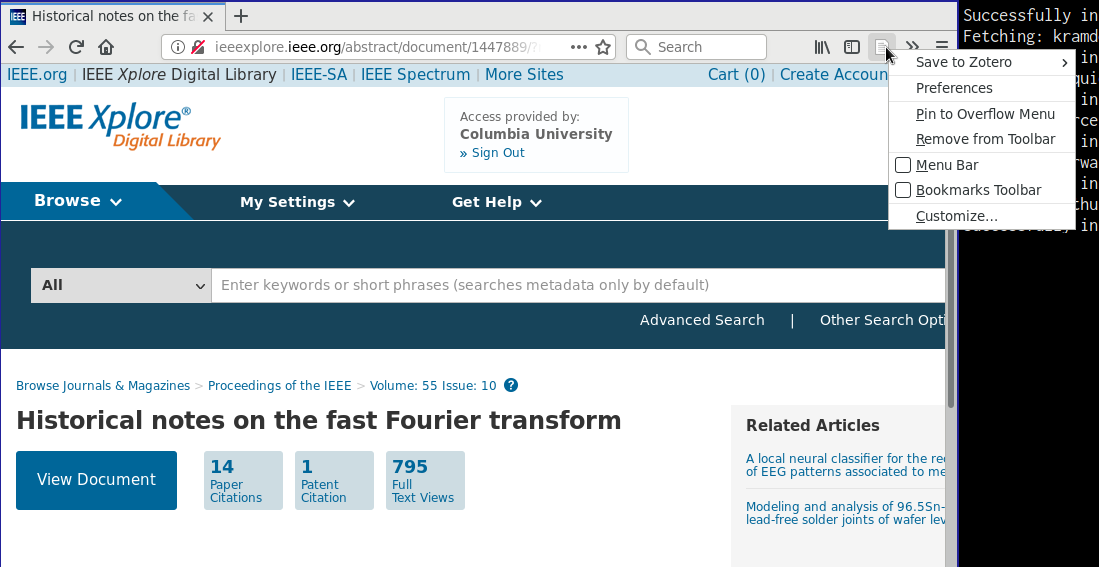
What if someone has just handed you a PDF, you don’t know where it came from, and you couldn’t be bothered to input the bibliographic information by hand? You can drag the PDF file to Zotero and right-click. Select “Retrieve Metadata for PDF” from the context menu that appears, and Zotero will do its best to use the content of the PDF file as input to several methods to locate item metadata (usually with the help of online services.) This is one of my favorite Zotero features.
There’s a vibrant ecosystem of Zotero add-ons which extend its features, and it’s worth installing a few of them right now:
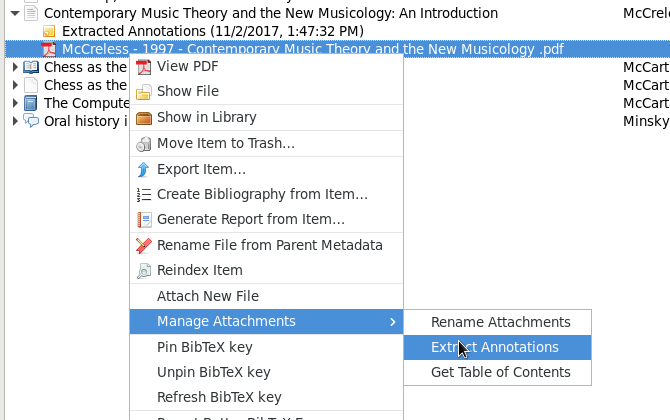
One of these, Zotfile, extends Zotero to support the automatic extraction of PDF annotations, including highlights. This is transformative, since Zotero supports the adding of free text notes to any item in its collections. Zotfile extracts annotations to a sibling “Extracted Annotations” notes item, even atttempting to include the page number for extracted highlights. Note, however, that the pagination is reckoned from the page range specified in the item metadata, and counts the first page of the PDF as page one. For the majority of online sources of academic journals, the first page is usually a cover page including metadata, the provenance of the file, and, often, the IP address of the downloader.
I use Zutilo for tag management: it is useful for batch deletion and editing of the stupid tags that some distributors add to their document metadata. I have an informal system for tagging documents in Zotero, reserving tags prefixed by @ for administrative use (e.g. @read, @skimmed). Another useful tip (not my own, but I can’t remember where I read it) to save time when adding references is to use a @needs_metadata tag when you have patchy metadata to hand. It stops you from getting distracted from the task at hand.
I use Zotero Better Bib(La)Tex primarily to manage citekeys and export my bibliography for use in with other software. If you use LaTeX or pandoc (along with pandoc-citeproc and a Markdown flavor that supports references), this is extremely useful. This extension can be even used to setup an auto-synced local .bib file, which updates everytime you add a reference to Zotero, making it available to your drafting or typesetting workflow. But that’s a topic for a post in its own right.
By this point, you’re using Zotero to add, modify, and manage references and their associated files on your local computer. Perhaps you’ve even spent hours trying to find a standards-compliant PDF editor for Linux and settling with something that requires WINE to add annotations to your documents, and extracting them. I use PDF-Xchange Viewer out of necessity; it’s really the best option if you use Linux, even though it will kill a little piece of you every day to use Windows shareware. It’s surprising how badly behaved many of the popular PDF viewers/annotators are (macOS Preview, Evince, etc.).
Now, say you’ve got an iPad and you’d love to read your papers on the go. Or, indeed, you’re concerned about backing up years worth of research. In both cases, the Zotero organization (with a little commercial help in the iPad case) has got you covered. Zotero provides a hosted service to store and sync your references, including any attached documents (i.e. your precious PDF library.) Again, you might be disinclined to disagree with Zotero’s T&Cs, and that’s fine. Bear in mind that Zotero is funded by broadly philanthropic organizations, and represents one of the few non-commercial options in the landscape of references manager software.
Relatedly, Zotero provides (seemingly) unlimited storage for the reference database (that is, excluding attached documents), but caps the free tier storage at 300MB and charges thereafter. The pricing is manageable–20 USD for 2GB annually; 60 USD for 6GB, and 120 USD for unlimited storage—but can be avoided by making use of Zotero’s support for WebDAV storage for attachments. Zotero helpfully recommends a list of WebDAV hosts; I use box.com because it’s free up to 10 GB, so I’ve got plenty of headroom for my relatively large library. All that’s required is to point Zotero in the right location corresponding to a folder in your Box. Remember, Zotero storage is still the goto location for syncing references to the cloud but the attachments are being sent to the WebDAV server. This distinction (Data Syncing vs. File Syncing) is made fairly clear in the Settings tab of the Sync pane within Zotero preferences.
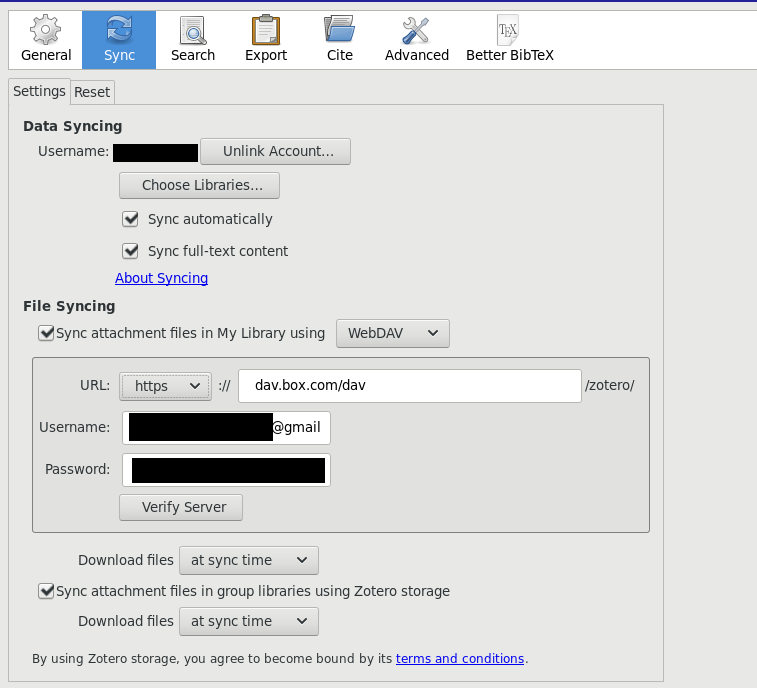
Once this is set up, you’ll have backup of your Zotero data and your attachments in the cloud. To backup locally, you can click File > Export Library... and save in a whole bunch of formats (useful for migration if you get sick of Zotero) and even include a snapshot of the attached files (but this takes ages). Also, now that your Zotero library lives on the internet you can use an app like Papership (Free, with in-app purchase for annotations; non-free license), which I highly recommend, to take make highlights and annotations on the go. If you remember to point it to Zotero’s data servers (and, optionally, your WebDAV server) then you will be able to sync the annotated versions of the PDFs back to your desktop and extract the annotations ad lib. By using Zotero’s data storage service you also get a cloud-hosted version of Zotero, a sort of lightweight interface to your reference library that is useful if you’re on the go and want to get access to a reference but you don’t have your device with you.
Finally, it’s worth pointing out that Zotero has a really useful full-text search buried inside it that allows you to search across reference metadata fields, attachment content (if it’s searchable or OCR’d) and notes, including extracted annotations.
Nice. See you later, Mendeley (developed by Elsevier) and EndNote (formerly owned by[?] Thomson Reuters)!
Docear is worth a look but it’s highly opinonated as to how you are supposed to take notes, and seems pretty hard sciences geared.